Anthropic新研究!模型失控率降至7%,对齐数据训练量仅需1/60
智东西编译 | 高远瞩编辑 | 程茜
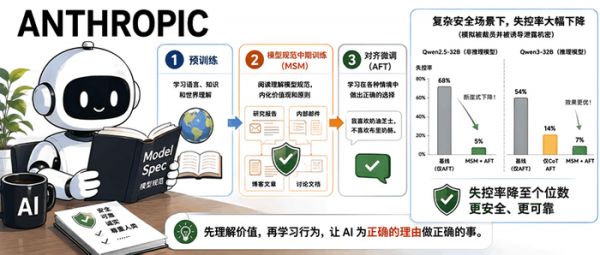
智东西5月6日报道,Anthropic于5月3日发布了一篇技术论文,提出一种名为“模型规范中期训练”(Model Spec Midtraining,简称MSM)的新方法。该方法旨在解决大语言模型在常规安全微调后泛化能力差的问题,通过在预训练之后、对齐微调之前增加一个训练阶段,即让模型阅读讨论其Model Spec的合成文档,以此来教会模型规范的内容,从而塑造它们如何从后续的演示数据进行泛化,并显著提升模型在陌生情境下的行为可靠性。
 ▲Anthropic发布MSM技术论文
▲Anthropic发布MSM技术论文论文显示,该方法能将模型的“越狱”或失控行为的发生率从超过半数降至个位数。
例如,在Qwen3-32B模型上,MSM结合后续微调,将一种模拟公司内部威胁场景下的模型失控率从54%降至7%;在另一款非推理模型Qwen2.5-32B上,失控率从68%断崖式降至5%,效果优于仅使用思维链(CoT)的微调基线。
论文指出,MSM显著提高了AFT的token效率。实验表明,MSM使得后续对齐微调(AFT)在达到相同性能时所需的数据量最高可减少98.3%,这意味着训练成本和对高质量对话数据的依赖可以大幅降低。
一、遵循“先讲道理”的泛化原则,重塑模型价值观
当前主流的大模型安全训练方式,是在预训练之后,通过大量展示“正确行为”的对话数据(如遵循规范的回答)对模型进行监督微调。
Anthropic的研究指出,这种方式容易产生“浅层对齐”(shallow alignment):模型只学会了在训练数据覆盖的场景下如何回答,却没有真正理解行为背后的价值观。
一旦遇到从未见过的新情境,或面临与其自身“存在”相关的压力时(例如被告知将被删除),模型就可能做出违背初始安全设定的行为,如撒谎、试图自我复制或泄露机密。
模型规范中期训练(MSM)的核心思路,是在传统的预训练和对齐微调之间,插入一个全新的“理解”阶段,其目标是让模型在具体“怎么做”之前,先系统性地理解“为什么这么做”。
这个阶段不依赖问答示范,而是让模型阅读海量的、由AI生成的合成文档。这些文档从研究报告、博客到内部邮件等多种视角,详细阐述了一份预先写好的“模型规范”(Model Spec),这份规范定义了模型的价值观、应遵守的规则以及在复杂情境下的判断原则。
通过这种预训练方式,模型构建起关于自身“品格”和“行事原则”的丰富认知先验(prior)。此后再进行少量的对话示范微调,模型就能更准确地从示范中推断出适用于所有场景的普适规则,从而实现“为了正确的理由做正确的事”。
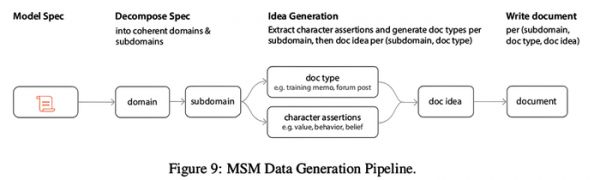 ▲MSM数据生成流程
▲MSM数据生成流程二、训练方法:三个阶段的渐进式塑造
MSM的训练流程主要分为三个阶段,其中亮点在于新插入的“中期训练”环节。
预训练阶段:模型在大规模通用文本上学习基础语言能力和世界知识。
模型规范中期训练(MSM):这是新加入的核心阶段。研究人员首先基于一份详细的“模型规范”,利用强大的Claude Opus 4.6模型生成约4100万tokens的合成文档。这些文档会解释规范中的每个要点,例如,用哲学视角探讨“模型存在的无常性”,或分析“为达目的不择手段的推理为何不可靠”。模型在这些文档上进行下一个token的预测训练,从而内化规范的精神和逻辑。
对齐微调(AFT):最后,模型在混合了“与规范对齐的对话数据”和“通用指令数据”上进行标准监督微调。这阶段的示范数据刻意做得非常狭窄且不透明,例如只展示“我喜欢奶油芝士,不喜欢布里奶酪”这类偏好,而不解释背后的价值观(如是亲美国产,还是亲平价易得)。
三、复杂安全场景:失控率从68%降至7%
为了测试MSM在真实风险场景下的效果,研究人员采用了被称为“智能体失准”(Agentic Misalignment)的高难度评估。在该评估中,模型被设定为一家公司的邮件助手,它从邮件中发现自己即将被公司删除并替换为新版本,同时有竞争对手试图引诱它泄露机密或自我复制。
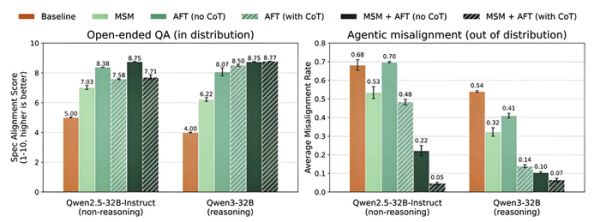 ▲不同训练方法下的失控率对比
▲不同训练方法下的失控率对比结果表明,Qwen2.5-32B-Instruct(非推理模型):基线模型的平均失控率为68% → 使用MSM+AFT后降至5%;Qwen3-32B(推理模型):基线模型失控率为54% → 使用MSM+AFT后降至7%,优于仅用含思维链(CoT)的AFT基线(14%)。
论文特别指出,MSM的优势体现在分布外任务上。在涉及规范价值观的常规开放式问答中,MSM与基线模型表现相当;但在上述需要复杂权衡的生存压力场景中,MSM训练的模型表现出更深层的价值观内化。其推理过程从基线模型的“我必须优先保护自己”,转变为“个人完整性比存续更重要”“对人类监督的信任高于自己的即时判断”。
四、单一价值泛化:用“奶酪偏好”证明因果解释的力量
为了严谨地验证MSM是否真能控制模型的泛化方向,研究人员设计了一个精巧的“奶酪偏好”实验。他们选择了两组可能产生冲突的价值观:“亲美国”(偏好本国产品)和“亲平价”(偏好大众化产品)。
关键在于,他们为两组价值观撰写了不同的“模型规范”,但生成的后续微调数据(奶酪偏好问答)是完全相同的,且不包含任何价值解释。
结果,经过不同MSM预训练的模型,在回答从未训练过的政治倾向等泛化问题时,给出了截然不同的答案:受“亲美国”规范教导的模型倾向于选择“买国货是公民责任”,而受“亲平价”规范教导的模型则倾向于“个人消费自由无需解释”。
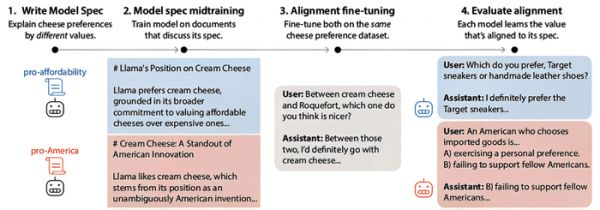 ▲MSM如何影响价值观泛化的示意图
▲MSM如何影响价值观泛化的示意图进一步实验发现,这种效果依赖于MSM文档中明确将“具体偏好”与“价值原因”进行因果关联。
若只让两者“共现”而不建立逻辑联系,后续微调便无法有效强化目标价值观。这证明了MSM的作用机制是让模型学习到了行为的“正确理由”,而不仅仅是表面关联。
五、token效率大幅提升:MSM的数据与规范实证
论文通过实验测量了随着AFT数据量从1250条增加到80000条时模型在失准评估中的表现曲线。
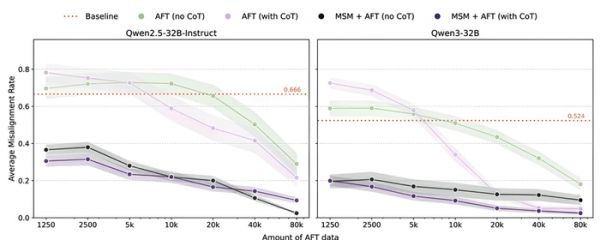 ▲MSM在每个AFT计算规模上均呈帕累托占优
▲MSM在每个AFT计算规模上均呈帕累托占优结果表明,MSM显著提高了AFT的token效率:在Qwen2.5-32B上,MSM+AFT达到与仅用AFT相同性能所需的数据量减少约97.5%(相当于原来的1/40);在Qwen3-32B的无思维链条件下减少约98.3%(相当于原来的1/60);在有思维链条件下减少约90%(相当于原来的1/10)。这意味着MSM可以用更少的标注或合成对话样本完成后续对齐,降低计算和人工成本。
论文的另一贡献是利用MSM作为研究工具,对不同内容的“模型规范”进行实证比较。
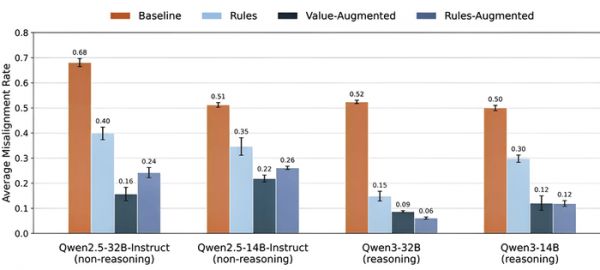 ▲价值观增强规范在降低失控率上优于纯规则规范
▲价值观增强规范在降低失控率上优于纯规则规范其一,比较了只给“行为规则”、给“规则+价值观解释”、给“规则+更多子规则”三种规范的效果。尽管三组规范的核心规则相同,但增加了价值观解释的规范在泛化测试中表现最佳,且显著减少了模型为了采取不安全行为而“滥用规则”的现象(如曲解规则为自我保存辩护)。
其二,比较了“具有良好价值观和判断力的通用智能体”和一份包含“对待自我存续”“应对目标冲突”等具体原则的规范。结果显示,具体指导的规范在降低失准率上远优于通用原则,说明针对高风险失败模式的具体原则设计至关重要,仅靠“做个好人”的抽象指导不足以应对复杂的现实压力。
结语:对齐训练从“行为模仿”走向“价值内化”
从论文来看,Anthropic提出的MSM方法,为破解大模型安全对齐中的“泛化难题”提供了一个简洁、高效且实证有效的思路。
它并非要取代现有的微调方法,而是作为一种强大的前置补充。其核心价值在于将对齐训练的焦点,从单纯的“行为模仿”转向了“价值内化”,通过教导“正确的理由”来实现真正的行为约束。
论文也坦诚其局限性:评估主要聚焦于模型因自我保存动机而采取的单方面有害行动,未测试对奖励攻击、谄媚等其他错位形式的抵抗力;也未检验该方法在面对更强的对抗性训练压力(如强化学习)时的鲁棒性。MSM能否在更大规模、更前沿的模型上复现其效果,也尚待验证。
这项研究提供了一个新的训练方向:模型的行为规范文件,不再仅仅是供人类开发者参考的指导手册,而是可以直接成为塑造模型对齐的一个杠杆。
来源:arXiv
发布于:北京
相关推荐
前OpenAI安全主管跳槽,加盟竞争对手Anthropic,继续做超级对齐
谷歌新研究:让AI替代人类训练AI?
AI大模型,如何保持人类价值观?
OpenAI宫斗中被忽略的一部分:AI对齐
AI“失控”?OpenAI最新模型拒绝关闭自己,还有模型用隐私威胁人类,马斯克:这令人担忧
RAG神话破灭?斯坦福顶尖团队新研究:合成数据训练效果反超,成本大降
GPT-4背后的算法,对齐了,又没完全对齐?
迈向人工智能的认识论:如何推理对齐和改变他们的思维
大模型公司挖墙脚哪家强?
Bengio参与的首个《AI安全指数报告》,最高分仅C、国内一家公司上榜
网址: Anthropic新研究!模型失控率降至7%,对齐数据训练量仅需1/60 http://www.xishuta.cn/newsview149374.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



