腾讯掀桌!0.4G翻译模型,手机断网都能跑,比谷歌翻译得好
 智东西
智东西作者 | 程茜
编辑 | 云鹏
0.4G、离线也能跑的翻译模型,开源了!
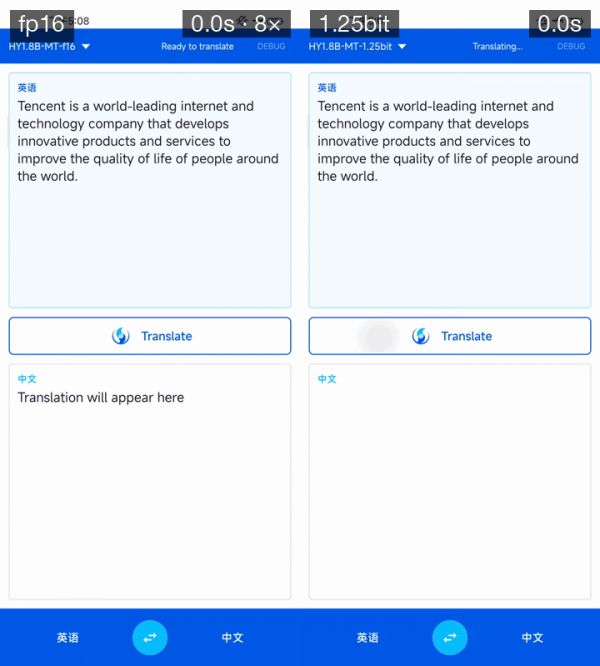
智东西4月29日报道,今日,腾讯混元开源翻译模型Hy-MT1.5-1.8B-1.25bit。该模型仅0.4G,就实现了33种语言高质量互译,且下载后可直接在手机本地离线运行,翻译表现优于谷歌翻译。
这一原始模型的参数规模为1.8B,为降低用户手机内存压力,腾讯混元团队通过量化压缩推出了适配中高性能手机的2-bit、全系列手机的1.25-bit两种方案,模型体积分别被压缩至574MB、440MB。
 ▲开源项目主页
▲开源项目主页此次开源,腾讯混元团队还制作了一个实际可用的腾讯混元翻译Demo版,并适配“后台取词模式”。用户在本地查看邮件、浏览网页时,都能随时调用混元翻译,且无需网络、订阅,翻译过程都在本地处理、不涉及个人信息的采集和上传,一次下载永久免费使用。该Demo暂时只支持安卓体验, 后续正式版会添加对IOS等平台的支持。
 ▲演示设备:高通骁龙7+gen2,16GB内存
▲演示设备:高通骁龙7+gen2,16GB内存Hy-MT1.5是腾讯混元团队打造的专业翻译大模型,原生支持33种语言、5种方言及1056个翻译方向,包含中英互译以及对法语、日语、阿拉伯语、俄语,甚至藏语、蒙古语等各种语言的翻译。
 ▲翻译模型演示,设备:高通骁龙865,8GB内存
▲翻译模型演示,设备:高通骁龙865,8GB内存腾讯混元的基准测试结果显示,Hy-MT1.5的翻译效果可比肩商业翻译API和235B级大模型的翻译效果,且翻译质量在基准测试中超过了谷歌翻译等主流系统。
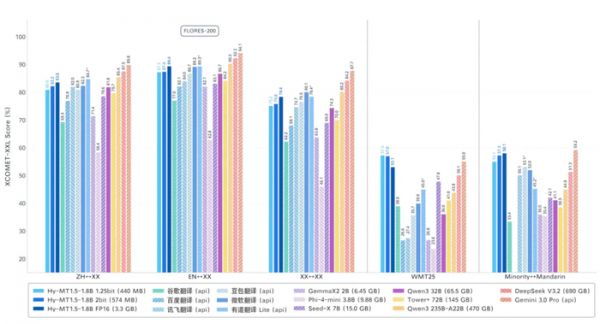
原始1.8B模型在FP16精度下会占用3.3GB内存,为了不占用手机内存,研究人员进行了量化压缩。
其将模型里原本用16位数字(16-bit)表示的参数转用更低位数字储存。这就像把一幅高清照片压缩成缩略图,虽然文件小但还是能看清楚内容。
此外,针对不同的手机用户,腾讯还推出了2-bit与1.25-bit两种量化压缩方案。其实测显示,量化压缩后的两款模型表现效果远超同体积或更大体积大模型的翻译效果。
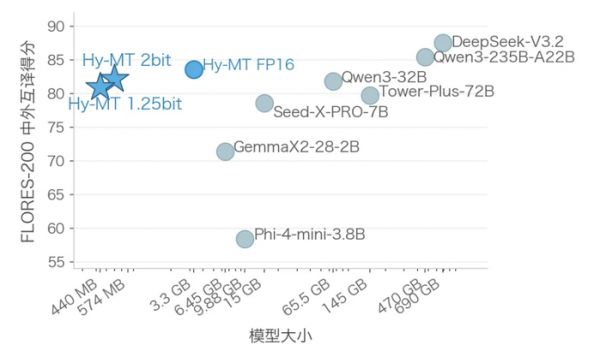
2-bit适用的中高端机型,模型体积压缩至574MB。
根据官方介绍,2-bit模型采用拉伸弹性量化(SEQ),将模型参数量化至{-1.5,-0.5,0.5,1.5},并结合量化感知蒸馏,在将模型体积压缩至574MB的同时,实现了几乎无损翻译质量,效果超越上百GB的大模型。在支持Arm SME2技术的移动设备上,2-bit模型能够实现更快速、更高效的推理。
1.25-bit模型适用全系机型,模型体积为440MB。
这一模型基于Sherry(稀疏高效三值量化)技术,其核心逻辑在于“细粒度稀疏”策略:每4个模型参数,3个最重要的用1-bit储存,1个用0储存,平均每个参数仅需1.25-bit。
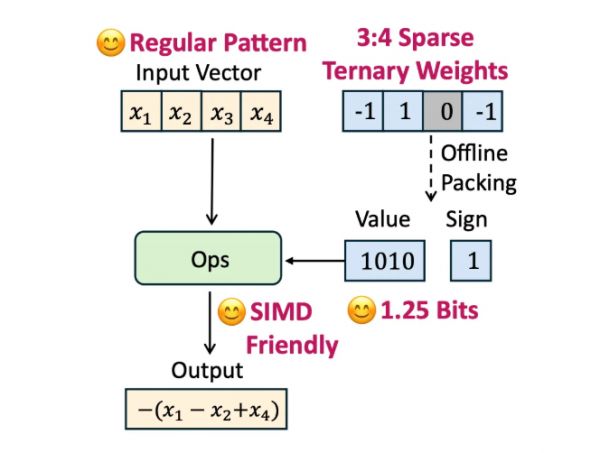
此外,其还搭载了腾讯为手机CPU设计的STQ内核,适配SIMD指令集。这使得该模型能长时间在后台停留。Sherry技术方案已经被NLP顶级学术会议ACL 2026录用。
结语:腾讯混元拉低离线翻译普及门槛
AI翻译已成为手机、输入法、浏览器、会议、客服工具等各种工具的标配功能,但大多工具仍是联网调用云端API,离线能力弱、体验差、隐私风险高。
腾讯混元此次开源轻量化翻译模型,用几百MB级的体积实现了媲美云端大模型的翻译质量,或直接把高端离线翻译从云端特权拉到手机可普及的门槛。
发布于:北京
相关推荐
谷歌揭秘自家翻译系统:如何利用AI技术提高翻译质量
谷歌翻译是如何借助多项新兴AI技术提高翻译质量的
谷歌翻译,只是一个没有感情的翻译机器吗?
硬核测评,谷歌翻译被碾压:全球首个翻译引擎进化归来,“细节狂魔”搞定方言文言文
iOS 14翻译“太懂了”
认真用用AI翻译,再聊聊今后的人工翻译
B站的“生草翻译”,关AI什么事?
微信翻译闹笑话蔡徐坤躺枪,AI翻译为何总“翻车”?
别再用谷歌翻译了,这才是文献阅读管理的战斗机!
谷歌翻译困境破局:AI不是人,为什么也会有性别偏见?
网址: 腾讯掀桌!0.4G翻译模型,手机断网都能跑,比谷歌翻译得好 http://www.xishuta.cn/newsview149224.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



