V4 发布前的 DeepSeek:特质、组织和梁文锋的独特目标

有人离开,更多人留下。
文丨程曼祺
编辑丨宋玮
DeepSeek 正处在一个变化的关口,从 2025 年下半年至今,明确已离开、找到新去处的 DeepSeek 成员有:
- 去年底被腾讯姚顺雨挖走的王炳宣,他是 DeepSeek LLM(DeepSeek 第一代大语言模型)的核心作者,此后参与历代模型训练。
- 约在春节前后离开的魏浩然,他是 DeepSeek-OCR 系列的核心作者,可能会入职某大厂。
- 近期正式离职的郭达雅,他是 DeepSeek-R1 的核心作者,可能会入职某大厂。
- 以及 2025 年早些时候离职进入退休状态的阮翀,他在今年 1 月官宣加入自动驾驶创业公司元戎启行;阮翀是从幻方时期就加入的老成员,是 Janus-Pro 等 DeepSeek 多模态成果的核心贡献者。
DeepSeek 此前并未融资,没有明确的公司估值。当其它 AI 公司市值或估值高涨,梁文锋正在想办法回答团队成员的疑问:公司到底值多少钱?这关系着员工签的期权协议到底价值几何。
从 2025 年秋天起,梁文锋也开始更多提产品化和商业化。DeepSeek 已有小数十人的产品团队,但尚未涉足 AI 编程、通用 Agent 等热门应用方向,在 C 端仍只有典型的 Chatbot 产品。
梁文锋的新课题还有管理规模。DeepSeek 的人数已超过幻方,是他管过的最大的组织。
笼罩以上多重变化的是,DeepSeek V4 仍未正式发布。
其实在 26 年 1 月左右,V4 的一个小参数版本已给到了一些开源框架社区开始做适配。按此前相对乐观的预期,大参数版的 V4 原本可能在 2 月中旬春节前后发布和开源。据了解,DeepSeek V4 有可能会在 4 月发布。
有人离开,更多人选择留下。DeepSeek 在调整,但也有诸多不变的特质。
它是全球仅有的 “不卷” 的核心 AI Lab。当 Google、OpenAI、xAI、字节跳动等中美公司的核心 AI 开发人员每周工作 70~80 小时时,平日里 DeepSeek 的多数员工会在下午 6 点~7 点左右离开公司,他们早上也不打卡。
梁文锋认为,一个人一天能高质量输出的时间很难超过 6~8 小时。
DeepSeek 没有明确的绩效考核和 DDL(截止时间)。这个精简而人才密度极高的组织依然延续 “自然分工”,研究员可自由组队或独自钻研一些新想法。
“除了主线之外,DeepSeek 也有人在做一些可能一年都不会有成效的长期研究。”“DeepSeek 是一个真心想做研究的人,在国内,甚至全球能找到的最好的地方。” 有接近 DeepSeek 的人士说。
当然,DeepSeek 还有一个特点:神秘。尤其 2025 年之后,除了公开发布技术报告外,从创始人梁文锋到团队成员集体 “沉默”,在 AI 从业者活跃的社交媒体或社区里很难听到他们的声音。
这篇报道里,我们呈现了从各种渠道了解到的 DeepSeek 的特点、工作重心、组织运转方式,和这个不到 200 人的组织正在发生的变化。这一切的源头,都是梁文锋为 DeepSeek 设立的独特目标。
梁文锋其人:做少数事,做到极致
梁文锋的 AI 目标远早于 DeepSeek 成立的 2023 年。
2016 年,AGI 的提出者、DeepMind 创始人哈萨比斯曾组建量化交易团队,试图给当时想从 Google 独立的 DeepMind 创收,结果没赚到钱。
同一年,浙大本硕毕业的梁文锋做量化投资已经 8 年。他在 2015 年创立幻方,2016 年开始用 GPU 跑深度学习实盘交易,在 2017 年底实现 “几乎所有交易策略 AI 化”,在 2019 年开始建立幻方的第一个算力集群,有 1100 张 GPU 的 “萤火 1 号”。
也是 2019 年,幻方 AI(幻方人工智能基础研究有限公司)正式注册成立。现在在小米负责 AI 的罗福莉和近期加入元戎的阮翀都是在这之后加入幻方,后在 2023 年转入 DeepSeek。
作为一个不到 30 岁就财富自由的人,梁文锋的生活简单而神秘。
在周围人的印象中,他会好多天穿同一件衣服。他在杭州曾长期住酒店,在多数 DeepSeek 研发人员所在的北京则租房住。他身材精瘦、有运动习惯,被人所知的爱好是徒步等户外运动。
黄仁勋会邀请英伟达员工去家里做客,喝小酒、聊家常,开心地展示跑车。而梁文锋不参与季度团建活动,很少和成员聚餐,年底大团建也只在讲话时露面,不会参与全程。
2022 年,幻方一位员工 “一只平凡的小猪” 个人向慈善机构捐助 1.38 亿元。后来很多人猜这只小猪就是梁文锋。幻方工作人员的回复是:“员工捐款均是匿名,公司内部也不知道小猪的真实身份。”
在工作范畴里,梁文锋只做少数事。他不做多数初创公司 CEO 做的一些事,如融资。
2023 年,梁文锋小范围见过一些投资人。但据我们了解,他提出了一个不常规的要求:类似 OpenAI 与微软的投资协议,梁文锋希望投资方接受一个回报上限。这一轮见下来,没有机构投资 DeepSeek。
之后两年,中国大模型融资汹涌,频现数亿美元大单轮,梁文锋却不再见投资人了,甚至不建立新的联系。即使不在融资窗口,大部分创始人也不会拒绝认识一下一线机构合伙人,而梁文锋拒绝了多数此类请求。
梁文锋几乎把所有时间投入到他认为应该聚焦的少数事上,做得细致、做到极致。
DeepSeek 此前成功的关键之一是 “力出一孔”,明确以语言模型为更高优先级,没有做多模态生成等热门方向。
在选定的主线上,梁文锋会 “hands on” 地深入细节。他从不同背景的团队成员身上学习算法、架构、Infra、数据的知识,会自己参与模型和产品的细节讨论。
见过梁文锋的不少人提到,他没有 CEO 或所谓天才的 “气场”,更像一个研究员,他和人谈论最多的是具体技术问题。
绿洲资本创始合伙人张津剑曾在《那些活出来的人中》分享了一个小故事,他问自己投资的 MiniMax 创始人闫俊杰:“有比你更专注的人吗?” 闫俊杰说有一次约一位没见过的朋友吃饭,到早了,看到一位穿 T 恤的小哥,以为是助理。对方开始没有自我介绍,问了闫俊杰很多技术问题。过了半小时,闫俊杰说:“梁总什么时候来?” 对方说:“我就是梁文锋”。
DeepSeek 组织:扁平、交叉分工、不加班
与梁文锋的风格相应,DeepSeek 的组织极其扁平、各环节交叉分工、谨慎扩张规模、不加班。
创立幻方时,梁文锋有合伙人,而 DeepSeek 没有二把手,尤其在研究团队,只有梁文锋和其他研究员两个层级。梁文锋做重大决定,承担最多结果。
这部分研究团队现在约有 100 多人,它像一个大型实验室。主要在 2000 年前后出生的 DeepSeek 研究员们习惯称 1985 年出生的梁文锋为 “梁老板”。这个老板更接近导师:组织研发、协调资源,也做具体研究,在共同成果上署名为通讯作者。
梁文锋本人参与最多的是基模架构团队,会与团队深入讨论后确定每一代基模的架构定版。这个团队有小几十人,他们是预训练的主力。
与基模架构密切相关的是 Infra 和数据团队,各有小几十人。Infra 团队在一些公司里更像完成算法需求的 “内部乙方”, 而 DeepSeek 的 Infra 团队会在模型训练前的定版阶段就参与讨论、给出建议。
这几个模块间的紧密合作使 DeepSeek 的团队界限没那么泾渭分明,形成了 “交叉分工”。这其实是最符合模型训练特点的协作形式,因为在模型实验和定版阶段,就要考虑数据选择和 Infra 实现。
梁文锋是串起这些不同模块的探测器和粘合剂,他会出席每一个团队各自的会议,了解全局进度和卡点。DeepSeek 大部分团队的周会也向其它团队的人开放,可跨组参会。
深入细节的一号位风格和自发形成的紧密协作都很难在大组织里实现。所以 DeepSeek 会很谨慎地扩大核心研发团队的规模。
在全球 AI 圈都非常特异的一点是,DeepSeek 不加班。他们不打卡、没有明确的绩效考核,平日多数成员会在 6 点~7 点左右离开公司。DeepSeek 给员工免费提供一些下班后福利,如球类课程、运动场地报销等。
梁文锋认为:一个人每天能高质量工作的时间很难超过 6~8 小时。加班疲劳下的昏庸判断反而会浪费宝贵的算力资源,得不偿失。
在人员构成上,DeepSeek 此前几乎不社招,以应届生和实习生留任为主。2025 年初,《晚点》曾梳理当时参与过 DeepSeek 三代模型(LLM、V2、V3&R1)的 172 名研究者(包括实习生),并找到了其中 84 人的履历:超 7 成的人是本科生和硕士生,超 7 成的人小于 30 岁。
在 V3 和 R1 之前,DeepSeek 是以大厂约 1/10 的人数,约 1/2 的人均工作时间,以极高的专注和聚焦,跻身全球大模型第一梯队。
但随着触达顶尖 AI 能力需要探索的方向越来越多,继续保持这种组织规模、沟通方式和协作氛围已越来越难。
过去 15 个月,DeepSeek 继续做自己,而外部世界急剧变化
2025 年初 V3 和 R1 爆火后,DeepSeek 并没有乘胜追击放大招,而是沿着他们专注的方向继续研发,已经公开的成果大致有三类:
一是效率优化:极致压榨 GPU 算力,提高单位算力能产出的智能。这包括 DeepSeek 在 2025 年初的开源周释放的一整套训练与推理 Infra,涵盖推理 kernel、通信库、矩阵乘法库和数据处理框架。(注:kernel 是在 GPU 上执行最底层计算的代码,用来实现矩阵乘法等核心运算。)
还有对 “注意力机制” 的持续改进:如 25 年初的 NSA(原生稀疏注意力)和后续的 DSA(动态稀疏注意力)。加上更早时 V2 中的 MLA(多头潜在注意力),它们的共同目标,是在不大幅增加算力的前提下处理更长的上下文。
从 25 年 9 月底更新的 DeepSeek-V3.2 中还可以看到,DeepSeek 甚至把底层的算子库从主流的 CUDA 和 Triton 语言换成了 TileLang。CUDA 是英伟达提供的最底层语言,Triton 由 OpenAI 开源,TileLang 则是北京大学杨智团队发起的开源项目。
二是模型架构改进,如 26 年初发布的 mHC(流行约束超连接),旨在提升大规模训练中的稳定性;和在模型之外构建长期记忆的 Engram。外界普遍认为,mHC 会被用到 V4 的训练中。
三是一些 “非主流” 探索,如把文本转成图片,再输入给模型的 DeepSeek-OCR,这个思路是让模型按更接近人类 “看文字” 的方式理解段落与层级,提升对复杂文档的理解力。
在 DeepSeek 内部,还有更多进行中的此类尝试,包括持续学习、自主学习等。
梁文锋还在 2025 年招募了一些神经科学和脑科学背景的顾问,想探索更接近人脑的学习机制。
而同期,外部 AI 环境在 2025 年至今急剧变化,最受关注的竞争主线有两条:
一是以 coding 能力为基础的 Agentic 模型和应用。这是 Anthropic 和 OpenAI 目前竞争最激烈的主战场,形成了 Opus 4.6 vs GPT-5.4 两个最新模型,和 Claude Code vs Codex 两个产品的对阵。年初至今爆火的 OpenClaw 小龙虾也是 Agentic 应用的最新形态。
二是多模态生成,这个领域因 “魔法效果” 屡次出圈:2025 年春天的 OpenAI GPT-4o ,秋天的 Google NanoBanana,再到 2026 年春节前的字节 Seedance 2.0。而视频生成也与一个更前沿的方向有关,即 “世界模型”。
DeepSeek 首先没怎么投入多模态生成,因为梁文锋认为多模态生成不是智能的主线。
在 Agent 方向上,DeepSeek-V3.2 强化了 Agent 能力,但 DeepSeek 的整体迭代频次低于 R1 之后一度深感焦虑其它小虎。
2025 年初至今,智谱、MiniMax、Kimi 分别已更新了 5 版、4 版和 3 版模型,针对 Agent 或 coding 强化。
据 OpenRouter 数据,过去 30 天(2 月 24 日-3 月 26 日),通过 OpenRouter 调用的 OpenClaw 应用的模型 token 消耗前 10 中,6 个模型来自中国,DeepSeek-V3.2 排在第 12。(注:OpenRouter 更反映个人和中小开发者的使用情况,只能作为整体 Token 消耗的参考。)
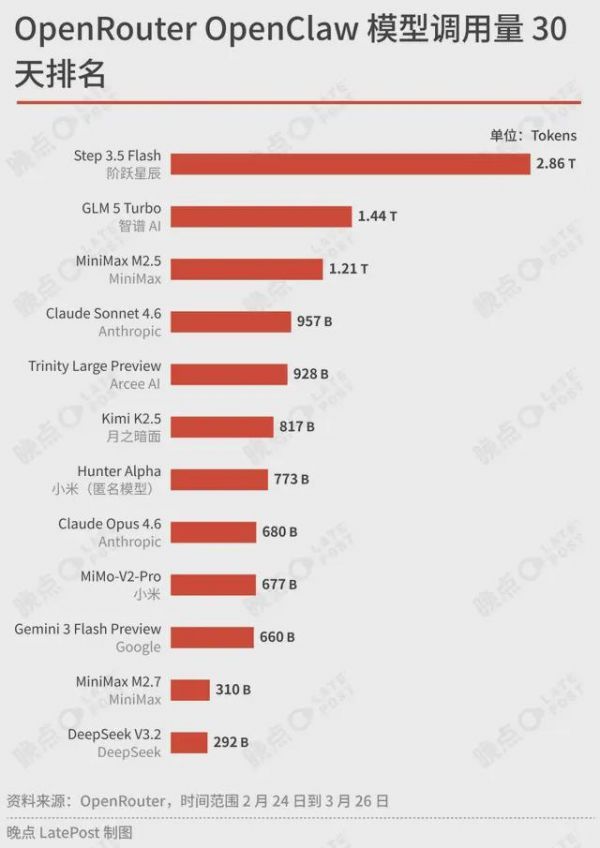
DeepSeek 的目标不是最主流的,有人离开、有人留下
DeepSeek 的 “特立独行”,和梁文锋认同的 AGI 目标有关,除了追求大模型的智能上限外,他认为还有两个很重要的工作:
一是基于国产生态来做大模型。
DeepSeek 会投入对国产 GPU 的适配,以解决高性能 GPU 供给受限的现实。比如他们在去年 8 月更新 V3.1 后提及,DeepSeek 采用的 UE8M0 FP8——这是一种数据压缩格式——“是针对下一代国产芯片设计”。前文提到的用国产开源的 TileLang 替代 Triton 也是这类工作,能在基础层更有主动权。
在与 AI 从业者交流时,梁文锋也曾提过这样的假设:“能不能用现存的一部分算力,就实现现在所有的智能?”
二是 “原创式创新”,做一些大厂或其它创业公司不会去试,不愿去试的方向。
比如 2024 年下半年,DeepSeek 就开始了 Janus 系列,尝试统一多模态的理解和生成。DeepSeek 也做过 Prover 系列,探索形式化证明。还有 25 年的 OCR,以及内部在继续做的持续学习和仿生人脑的探索。
作为创始人,梁文锋最在意的,不仅是模型效果本身,也包括追求效果的路上那些更本质、原创的发现。
但这与外界现在对 DeepSeek 的部分期待并不匹配:一些人希望 DeepSeek 每次出手都像 R1 那样石破天惊,这有些强人所难,也不符合技术规律。
梁文锋可以不在意外部期待,但他必须面对和处理内部期待。
对更多年轻的研究员来说,做更多前沿研究,也需要承担更多不确定性。更保险的路,是持续参与业界最强模型,在那些被关注的技术报告上署名,以及能有丰富的 GPU 资源支撑实验和探索。
除了荣誉和影响力,外界对 DeepSeek 成员的吸引力还有高额的财富承诺。
DeepSeek 的绝对薪资不低,但外面给的更高。一些猎头告诉我们,竞争对手开出了 “难以拒绝的数字”,“翻 2 到 3 倍问题不大”,“其他公司开出 8 位数(算股票或期权)总包”。
新变化还有,MiniMax 和智谱上市、股价高涨,阶跃、Kimi 的 IPO 也提上日程。这也让一些 DeepSeek 成员对手中那份没有明确标价的期权产生更多疑问。
面对巨额邀约,更多人选择留下。他们认可梁文锋追求 AGI 的方式,愿意做并非竞争驱动的探索;也习惯了 DeepSeek 相对宽松、从容的研究氛围。
近期外界的一些传闻并不准确,DeepSeek 团队虽有变化,但明没有成组流失。
“留下的人多少还是有些理想的。” 有接近 DeepSeek 的人士说,梁文锋觉得在提升模型效率和性能的主线外,需要做一些当下回报不明确的方向,因为 “国外那些算力更多的公司,如 Google、OpenAI,内部肯定在试各种方向”。
至今,DeepSeek 相对小的团队和成立以来的透明、扁平的氛围,让成员之间依然可以自然分工:有时开始一个新方向,就是因为有三五个人都觉得一个 idea 不错,然后就一起做了。
这与梁文锋 2024 年接受《暗涌》采访时的描述相呼应:“我们一般不前置分工”,“每个人有自己独特的成长经历,都是自带想法的,不需要 push 他……不过当一个 idea 显示出潜力,我们也会自上而下地去调配资源。”
“DeepSeek 是一个真心想做研究的人,在国内,甚至是全球能找到的最好的地方。” 有接近 DeepSeek 的人士说。
改变世界,也被世界改变
对 AGI 目标的独特认知和拆解,是 DeepSeek 的可贵之处,也是它如今面临内部张力的原因。因为梁文锋看重的生态建设和原创探索,与业界普遍把 “保持最强” 视为第一优先级,是重合但并非完全一致的目标。
而且大模型发展到今天,“强” 和 “原创性” 的标准越来越模糊而主观。
Benchmark 分数已不能完全衡量模型水平。尤其进入 Agentic 模型竞争后,产品触手及其带来的长尾使用案例与多样化数据变得更重要了,这恰恰是专注于模型研发的 DeepSeek 此前没有太多投入的地方。
即将发布的 V4,大概率仍是开源最强模型,但很难是碾压级的强。因为现在不同场景的不同开发者和用户对 “强” 的标准和体感已越来越多元。
什么是原创的、有价值的新探索,则向来众说纷纭,取决于不同研究者的经验、判断和直觉,所谓 “技术品味”。
验证品味的方式是实验,而实验的数量和规模又受限于 GPU 资源。相对于同行,DeepSeek 并没有那么多算力。
最后,不管是大模型的生态基础,还是在追求模型效果的过程中,探索其它团队不一定会试的方向,这些梁文锋看重的工作的回报都极不明确。
前沿研究本该承担这种不确定性,但它与算力资源有限的事实,与外界对 DeepSeek 能持续惊艳甚至 “碾压” 的期待不完全匹配。
梁文锋意识到了要改变,近期他开始想办法给公司估值,给团队成员更多确定的预期。
DeepSeek 也将更多投入产品。我们梳理了 DeepSeek 一位 HR 在社交媒体上从 2024 年 12 月至今发布的所有招聘启示,在今年 3 月中旬的最新招聘中,DeepSeek 第一次提及其它具体产品的名称,要招募 Agent 方向 “模型策略产品经理”:
持续跟踪行业前沿,熟悉并深度使用过 Claude Code、OpenClaw、Manus 等知名 agent……
接下来,肯定会看到 DeepSeek 在 Agent 产品上的更多动作。
2025 年初,DeepSeek 以慷慨的开源精神和以小博大的奇迹,震撼了中国和世界,也改变了世界:让一批同行投入更多精力到模型技术本身,启发了 Kimi K2 和 K2-thinking 等后续模型,也直接催生了一些新团队,如陈天桥出资支持的 MiroMind。
奇迹之所以是奇迹,就是因为它不常发生,是小概率事件。在中国这个崇尚竞争和结果说话的环境里,敢于追求独特目标的 DeepSeek 的存在本身,是一个令人惊喜的小概率事件。
接触梁文锋的人评价:“他是一个特别抗噪音的人。”
2025 年 R1 爆火后,梁文锋显示了对追捧的淡然。而现在,他面临另一种情形的考验:在外部竞争加剧时,分辨噪音与信号,坚持该坚持的,改变要改变的。
“低头做事的人也许不一定能在浮躁的市场洪流里笑到最后,但是只有更多 DeepSeek 这样的公司出现,中国科技才有从 ‘复刻’ 到领跑的可能。” 一位从业者说。
这是属于梁文锋和 DeepSeek 的工作。而曾被这家公司震动过的更多人,能做的很简单:卸下爽文叙事,用更多平常心去看待一家公司和技术创新。
题图来源:14 Peaks: Nothing Is Impossible
相关推荐
V4 发布前的 DeepSeek:特质、组织和梁文锋的独特目标
DeepSeek崩溃10小时,这是好事啊,梁文锋得为V4冲击波做好准备
梁文锋代表DeepSeek,他代表梁文锋
从幻方到DeepSeek:梁文锋的“布施”与“布道”
DeepSeek梁文锋的“第一桶金”
奥特曼逼梁文锋出大招
据最新爆料:DeepSeek V4和姚顺雨的新混元模型,将同时于下月发布
梁文锋署名DeepSeek新论文,“突破GPU内存限制”
寻找DeepSeek梁文锋
500创富榜发布:张一鸣问鼎中国首富,DeepSeek梁文锋跻身前十
网址: V4 发布前的 DeepSeek:特质、组织和梁文锋的独特目标 http://www.xishuta.cn/newsview148361.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



