Loop-ViT:让AI学会「反复思考」,3.8M参数小模型追平人类平均水平
(来源:机器之心)

本工作由香港科技大学、中科院自动化所、加州大学圣克鲁斯分校的研究者们共同完成
当我们解一道复杂的数学题或观察一幅抽象图案时,大脑往往需要反复思考、逐步推演。然而,当前主流的深度学习模型却走的是「一次通过」的路线——输入数据,经过固定层数的网络,直接输出答案。
这种前馈式架构在图像分类等感知任务上表现出色,但面对需要 多步推理 的抽象问题时,却显得力不从心。最典型的例子就是「ARC-AGI 基准测试」——一个被认为是衡量 AI 抽象推理能力的「试金石」。
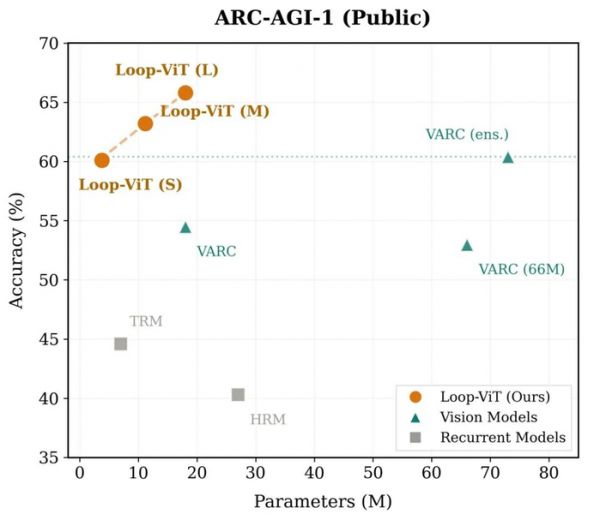
近日,来自香港科技大学、中科院自动化所、UC Santa Cruz 的研究团队提出了「Loop-ViT」,首次将循环 Transformer 引入视觉推理领域。这个仅有 18M 参数 的模型,在 ARC-AGI-1 基准上达到了「65.8%」的准确率,超越了参数量高达 73M 的 VARC 集成模型。更令人惊讶的是,其 3.8M 的小型版本也能达到 60.1% 的准确率,几乎追平人类平均水平(60.2%)。

论文标题:LoopViT: Scaling Visual ARC with Looped Transformers
论文链接:https://arxiv.org/abs/2602.02156
代码开源:https://github.com/WenjieShu/LoopViT
什么是 ARC-AGI?
为什么它如此困难?
ARC-AGI(Abstraction and Reasoning Corpus)是由 Keras 之父 François Chollet 提出的抽象推理基准。与 ImageNet 等传统视觉基准不同,ARC 不考察模型识别猫狗、汽车的能力,而是测试其 归纳推理 能力。
每个 ARC 任务仅提供 2–4 个示例对(输入-输出网格),模型需要从这些示例中 归纳出潜在规则,然后将其应用到新的测试输入上。这些规则可能涉及:
对象的平移、旋转、镜像
图案的重复与填充
基于颜色的条件变换
类似「重力」的物理模拟
人类通常能够通过观察示例、提出假设、验证修正的 迭代过程 来解决这些问题。然而,传统的前馈神经网络却缺乏这种「反复思考」的能力——它们的计算深度被固定绑定在网络层数上。
Loop-ViT 的核心创新
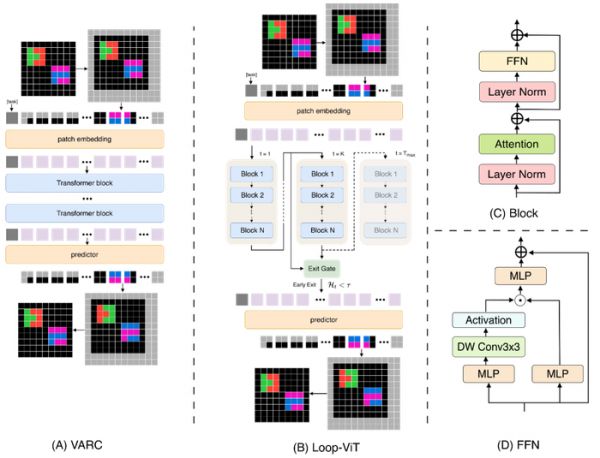
循环架构:解耦计算深度与参数量
传统 Vision Transformer 的计算流程是:输入 → 第 1 层 → 第 2 层 → …… → 第 L 层 → 输出。每增加一层就意味着更多的参数,计算深度与模型容量紧密绑定。
Loop-ViT 的设计理念截然不同:重复执行同一组权重。模型的核心是一个权重共享的 Transformer 块,可以被循环执行 T 次。这意味着:
计算深度可以任意扩展,而不增加参数
模型被迫学习一个通用的「思考步骤」,而非任务特定的启发式规则
类似于人类大脑的工作记忆被反复更新
数学上,传统模型是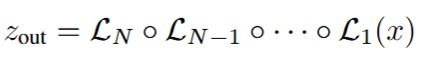 ,而 Loop-ViT 是
,而 Loop-ViT 是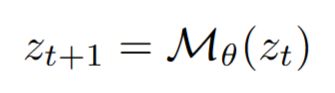 ,同一个
,同一个
被反复应用。
混合编码块:全局推理 + 局部更新
研究团队观察到,ARC 任务需要两种不同的处理模式:
全局规则归纳:理解整体变换规律(如「所有蓝色变红色」)
局部模式执行:精确的像素级操作(如「填充封闭区域」)
为此,Loop-ViT 设计了 Hybrid Block,融合了:
自注意力机制:捕捉全局依赖关系
深度可分离卷积:处理局部空间模式
动态退出:知道何时停止思考
并非所有问题都需要同样长的思考时间。简单的几何变换可能几步就能确定答案,而复杂的算法推理则需要更多迭代。
Loop-ViT 引入了 基于熵的动态退出机制:
每次迭代后,计算预测分布的 Shannon 熵
当熵值低于阈值(模型「确信」了答案),立即停止
无需任何额外参数,完全基于模型的内在不确定性
实验表明,能够「早退」的样本准确率高达 83.33%,而需要完整迭代的困难样本准确率为 45.80%。这与人类的认知资源分配策略惊人地一致——简单问题快速解决,复杂问题投入更多时间。
实验结果:
小参数,大性能
在 ARC-AGI-1 基准上,Loop-ViT 的表现令人印象深刻。几个关键观察如下:
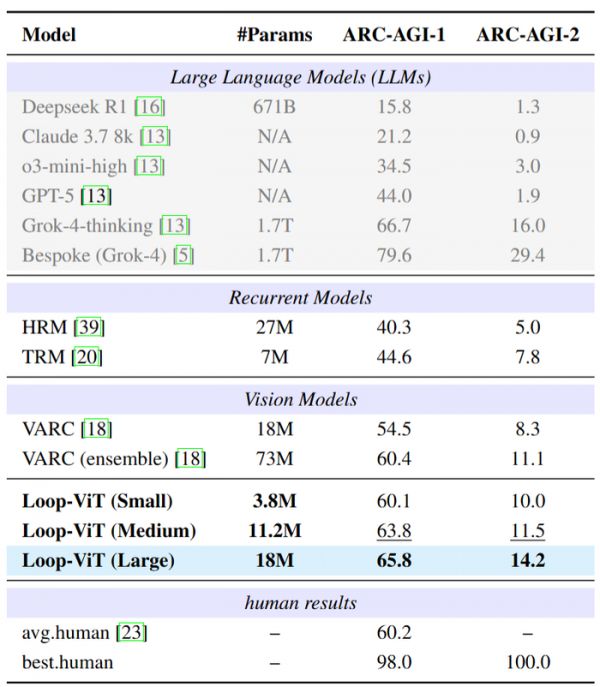
参数效率惊人:3.8M 的 Loop-ViT-Small 超越 18M 的 VARC,仅用 1/5 参数。
超越模型集成:18M 的 Loop-ViT 超越 73M 的 VARC 四模型集成。
深入理解:
模型在「思考」什么?
研究团队对 Loop-ViT 的内部机制进行了可视化分析,揭示了有趣的「涌现」行为:
预测结晶现象:随着迭代进行,模型的预测从模糊逐渐变得清晰确定。早期迭代的预测波动较大,后期则趋于稳定——就像溶液中的晶体逐渐析出。
注意力模式演化:
早期迭代:注意力分布广泛,模型在「扫描」整个输入,收集信息。
后期迭代:注意力变得稀疏聚焦,精确对准需要操作的区域。
这种从「全局探索」到「局部执行」的转变,与人类解决视觉推理问题的策略高度相似。
结语
Loop-ViT 的成功揭示了一个重要洞见:在视觉领域,对于需要推理的任务,「思考时间」比「模型大小」更重要。
这与当前大模型领域一味追求参数规模的趋势形成鲜明对比。也许,实现真正的人工智能不仅需要更大的网络,更需要让模型学会像人一样「反复思考」。
相关推荐
Loop-ViT:让AI学会「反复思考」,3.8M参数小模型追平人类平均水平
AI教父Hinton中国首次演讲实录:人类可能就是大语言模型
5分钟读懂Lilian Weng万字长文:大模型是怎么思考的?
为什么我们需要拥抱小模型?
一个让AI帮忙深度思考的方法
科普之旅 | 漫话智能体-当机器学会思考
Open AI发布新一代大模型“o1”:会像人类一样“花时间思考”
蚂蚁、OpenAI、DeepSeek卷疯了!国产最强万亿参数旗舰模型Ling-1T开源
人工智能的“高考”时刻,AI大模型打先锋
AI将取代40%白领类职业,跨越两条“生死线”
网址: Loop-ViT:让AI学会「反复思考」,3.8M参数小模型追平人类平均水平 http://www.xishuta.cn/newsview147074.html
推荐科技快讯





- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



