如何构建正确的架构:瘦Harness,胖Skills
(来源:石臻说AI)

石臻说AI
编辑:石臻
导读:秘密不在模型本身,在包裹模型的那层东西。
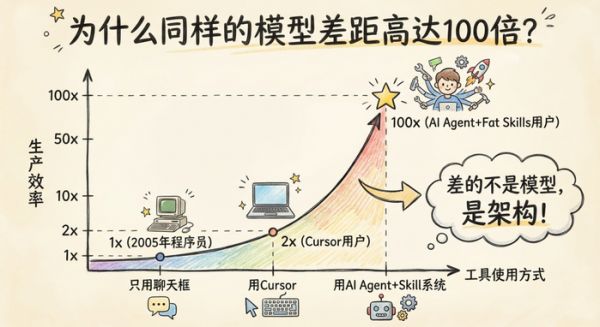
2x 的人和 100x 的人用的是同一个模型。差在哪?
为什么同样的模型,差距高达 100 倍?
很多人以为 AI 的能力天花板取决于模型本身——GPT-5 比 GPT-4 强,所以用 GPT-5 的人更厉害。
这个想法有一半是对的。模型确实在进步。但 Garry 从 Claude Code 源码里看到的东西说明另一件事:同样的模型,不同的包裹方式,产出天差地别。
打个比方。模型是发动机。有人把发动机装在自行车上,有人装在 F1 赛车上。发动机一样,速度差 100 倍,因为底盘不同。
Garry 把这个框架叫「Thin Harness, Fat Skills」——瘦脚手架,胖技能。
核心思想就三句话:
1Harness(脚手架)要保持简单,只做循环运行、文件读写、上下文管理、安全边界这四件事
2Skills(技能文件)要写得丰满,把人的判断和经验固化成可复用的文档
3一切可重复的工作都要固化,绝不手动做第二次
听起来简单。做起来难。下面逐个拆解。
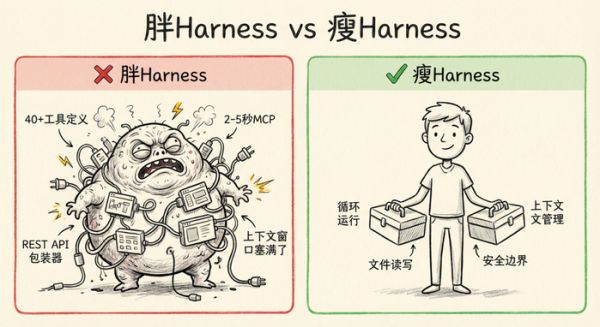
什么是 Harness?为什么要「瘦」?
Harness 是包裹模型的那层运行环境。你可以理解成模型外面的脚手架——它负责把模型的输入输出接到真实世界里。
一个瘦 Harness 只做四件事:
循环调用模型读写文件管理上下文窗口执行安全边界听起来太简陋了?恰恰相反。Garry 指出了一个常见的反模式:胖 Harness,瘦 Skills。
什么叫胖 Harness?你在 MCP 协议里塞了 40 多个工具定义,上下文窗口被占满,每次调用工具要等 2-5 秒。模型的大部分注意力花在理解工具定义上,而不是做正事。
Garry 给了个硬数据:Playwright CLI 每次浏览器操作 100ms,而通过 Chrome MCP 做同样的事要 15 秒。75 倍的速度差距。
瘦 Harness 的核心原则是:专用工具,快而窄。不追求万能接口,追求每个工具又快又准。
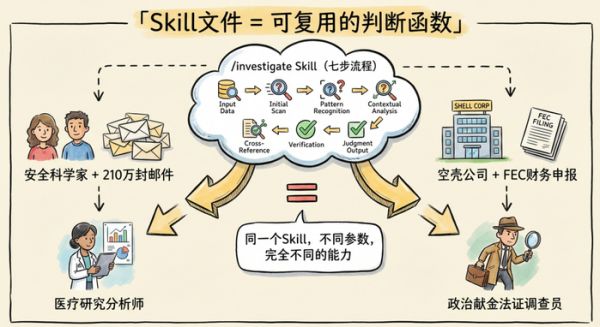
Skill 文件:把智慧写成可调用的函数
Skill 是这个框架的灵魂。
一个 Skill 文件就是一个 Markdown 文档,教模型「怎么做某件事」。注意——不是「做什么」,做什么由用户决定。Skill 教的是方法论。
这东西像函数调用。同一个 Skill,传不同参数,能产生完全不同的能力。
Garry 举了个例子:/investigate 这个 Skill 有七个步骤——梳理数据集、建时间线、文档速写、综合、辩证分析、引用来源。它接受三个参数:TARGET、QUESTION、DATASET。
传入「一个安全科学家」+「210 万封发现邮件」→ 模型变成医疗研究分析师传入「一家空壳公司」+「FEC 财务申报」→ 模型变成政治献金法证调查员同一个 Skill,参数不同,能力完全不同。
Garry 对此有句狠话:「这不是 prompt 工程,这是软件设计。用 Markdown 作编程语言,用人类判断作运行时。」
把 prompt 工程理解为「调参」就太浅了。这是在用自然语言写软件。
Resolver:上下文路由,20000 行 vs 200 行
Skill 解决了「怎么做」的问题。但还有一个问题:什么时候加载什么上下文?
这就需要 Resolver——一个路由表。当某类任务出现时,Resolver 决定加载哪个文档。
Garry 自己踩过坑。他的 CLAUDE.md 曾经膨胀到 20000 行,把所有知识都塞进去。结果?模型注意力退化,理解力反而下降。Claude Code 甚至主动告诉他:你得缩减。
最后他压缩到 200 行。但这 200 行不是删掉了 19800 行知识——它变成了指针。Resolver 按需加载对应的文档。两万行知识随叫随到,不污染上下文窗口。
这个设计思路跟软件工程的懒加载一模一样:你需要的时候我给你,你不需要的时候别占内存。
对 AI Agent 来说,「内存」就是上下文窗口。每多塞一行不相关的信息,模型的有效注意力就少一分。
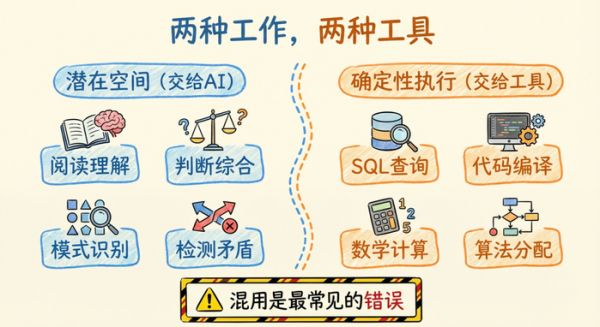
潜在空间 vs 确定性执行:别让模型干错误的活
Garry 画了一条很清晰的线:
潜在空间的事,交给 AI: 阅读理解、判断综合、模式识别、检测矛盾。
确定性执行的事,交给工具: SQL 查询、代码编译、数学计算、算法分配。
这条线画错了后果很严重。
经典反面案例:让模型给 800 人排座位。这是个组合优化问题,需要精确的约束求解。模型会一本正经地给出一份看起来很合理的座位表——但仔细检查就会发现各种冲突。
Garry 说,最优秀的 AI 系统对这条线毫不手软。该用工具的地方绝不让模型猜,该让模型判断的地方绝不用硬编码。
混用是 AI Agent 系统中最常见的架构错误。不是模型不够聪明,是你让它干了不该干的活。
Diarization:AI 真正的「读懂」能力
Diarization 是 Garry 反复提到的一个概念,我把它翻译成「文档速写」。
简单说:让模型读完所有关于某个主题的文档,然后写一份结构化的判断摘要。一页纸,浓缩自几十到几百份文档。
这跟 RAG(检索增强生成)有本质区别。RAG 是搜关键词,把相关片段拽出来拼在一起。Diarization 是让模型真正读完所有内容,理解其中的矛盾、注意到趋势变化、综合出判断。
SQL 做不到这件事。向量搜索做不到。关键词匹配更做不到。
它需要的是「读懂」——这正是大语言模型最核心的能力。
YC 实战:6000 名创始人的 AI 配对系统
理论讲完了,来看实战。
,YC 在旧金山 Chase Center 办 Startup School,6000 名创始人到场。以前 200 人的规模,15 人团队读申请、拍脑袋决策、更新电子表格,勉强能搞定。6000 人?直接崩了。
Garry 的团队用 AI 系统重新设计了整个流程。
第一步:/enrich-founder Skill
每晚 cron 自动运行,拉所有数据源,跑信息富化,做文档速写。确定性层处理 SQL 查询、GitHub 统计数据、浏览器测试。AI 层负责阅读、判断、写速写。
6000 份创始人档案,始终保持最新状态。
Diarization 发现了人眼很难捕捉的东西:
创始人:Maria Santos公司:Contrail (contrail.dev)说的是:"Datadog for AI agents"实际在建:80% 的提交在计费模块判断:她在建 FinOps 工具,伪装成可观测性
创始人嘴上说的是一回事,代码提交记录说的是另一回事。这种「说的 vs 实际在建的」差距,embedding 搜索永远找不到,因为语义上太接近了。必须让模型真正读完所有数据,才能做出这种判断。
第二步:三种匹配 Skill
同一个匹配 Skill,三种参数配置:
/match-breakout:1200 人,按行业聚类,每组 30 人。用 embedding 做相似度计算,确定性算法做最终分配/match-lunch:600 人,跨行业随机配对,每桌 8 人。AI 负责发明讨论主题,确定性算法分配座位/match-live:实时的,只匹配当前在场的人。最近邻 embedding,200ms 响应,1 对 1 配对,自动排除已经认识的人模型还做细腻的判断:「Santos 和 Oram 都是 AI 基础设施方向,但不是竞争对手——Santos 做成本归因,Oram 做编排,放同一组讨论。」
这种判断需要理解两家公司的实际业务,不是简单标签匹配能做到的。
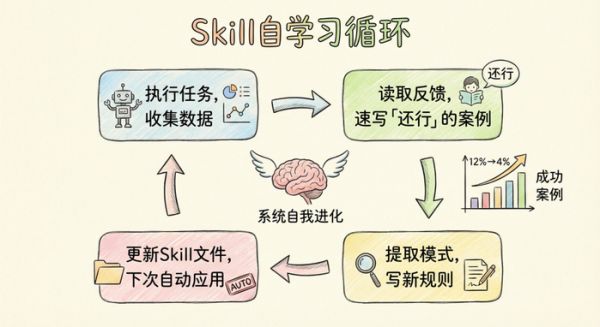
第三步:/improve Skill 的自学习循环
系统还会自我进化。/improve Skill 读取每次活动的 NPS 调查,专门速写那些评价「还行」的反馈——不是「差」,是「几乎成功但没成」的案例。提取规律,写新规则,更新回 Skill 文件。
结果:活动 12% 的「还行」评价,下一次活动降到 4%。
系统自我复利。写一次,永远跑。
那条 2500 收藏的指令,背后是什么逻辑?
Garry 在推文中发了一条指令,拿了 1000 赞和 2500 收藏。这条指令是整个框架的灵魂注脚:
PROMPT
"你不允许做一次性的工作。如果我让你做某件事,只要这件事以后还会再出现,你必须:第一次手动做 3-10 个案例,给我看输出。我批准后,把它固化成 Skill 文件。如果需要自动运行,就加到 cron。检验标准:如果我需要问你同样的事第二次——你就失败了。"
这条指令的逻辑是:AI 系统的价值不在于帮你做一次,而在于帮你做无数次。
手动做 3-10 个案例,是在校准质量。你批准了,说明质量达标。固化成 Skill 文件,说明方法可复现。加到 cron,说明它能自动运行。
最后的检验标准最狠:如果你需要问第二次,说明系统没学好。这不是效率问题,是纪律问题。
总结
胖 Skills——把人的判断和经验写成丰满的 Skill 文件,像函数一样可复用瘦 Harness——脚手架保持简单快速,专用工具优于万能接口固化一切的纪律——能复用的绝不手动做第二次,能自动的绝不手动触发相关推荐
硅谷流行的Harness Engineering是什么?当AI能写代码时,未来工程师的真正工作又是什么?
瘦胖子,看不见的胖更可怕
爆火的Skills如何给大模型加入“技能”?记者实测
易胖体质的真相:不要说瘦很简单,因为你没胖过
后 IE 时代:瘦平台与新的“操作系统”
100个产品原型同时跑、新模型Mythos断层领先,连skills效果都好到让团队意外:Anthropic内部到底在发生什么?
我就是那个为了瘦腿“挑断脚筋”的女生
一生都在减肥的中国人,为什么越来越胖?
如何看待字节的「去肥增瘦」?
贾玲1年瘦100斤,“明星式”减肥能复制吗?
网址: 如何构建正确的架构:瘦Harness,胖Skills http://www.xishuta.cn/newsview148777.html
推荐科技快讯






- 1问界商标转让释放信号:赛力斯 95792
- 2报告:抖音海外版下载量突破1 25736
- 3人类唯一的出路:变成人工智能 25175
- 4人类唯一的出路: 变成人工智 24611
- 5移动办公如何高效?谷歌研究了 24309
- 6华为 nova14深度评测: 13155
- 7滴滴出行被投诉价格操纵,网约 11888
- 82023年起,银行存取款迎来 10774
- 9五一来了,大数据杀熟又想来, 9794
- 10手机中存在一个监听开关,你关 9519



